인공지능, AI
4차 산업혁명 시대에 살고 있는 지금의 우리는 현실속에서 체험할 수 있는 다양한 정보기술의 신기술들을 경험하며 그리고 실제 체험하며 살아가고 있습니다. 이제는 용어자체가 전혀 생소하지 않게 다가오고 우리가 인지하지 못하는 가운데 점점 우리생활 깊은곳까지 점유해 갈 수 있는 대표적인 정보기술의 하나가 바로 인공지능, AI라는 것입니다.
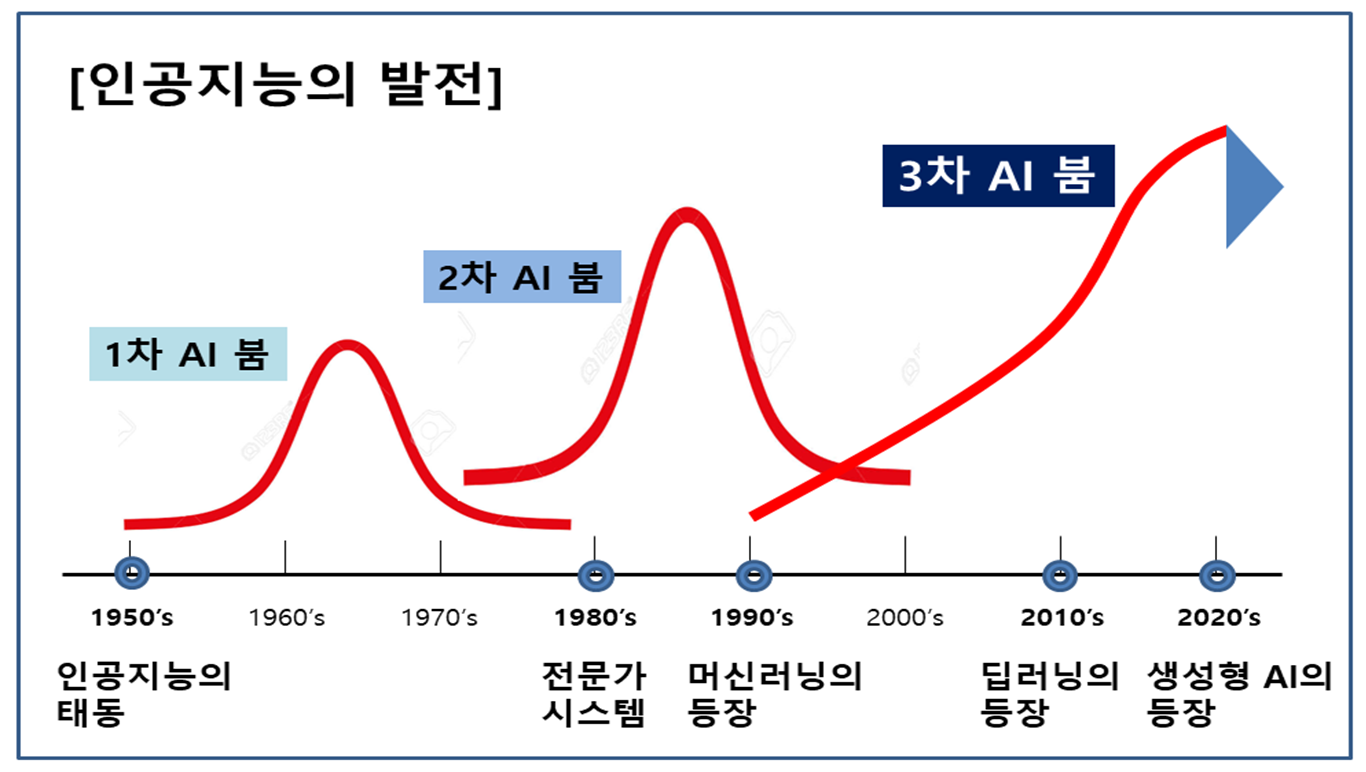
인공지능(Artificial Intelligence)은 사람처럼 학습도 하고 추론(생각과는 조금 차이가 있는)할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술입니다. 인공지능의 역사는 지금으로부터 약 80년 전부터 기초적인 연구의 한 분야로 시작되었으며, 사람과 비슷한 지능적인 시스템을 만들고자 하는 시도들이 있어 왔습니다.
1) 1943년: 워런 매 컬러(Warren McCulloch)와 월터 피츠(Walter Pitts)는 최초로 뇌의 뉴런 개념 발표
2) 1950년: 컴퓨터의 아버지라 불리우는 앨런 튜링(Alan Turing)이 인공지능이 사람과 같은 지능을 가졌는지 테스트할 수 있는 유명한 튜링 테스트(Turing Test)를 발표
3) 1956년: 많은 과학자가 참여한 다트머스 AI 콘퍼런스(Dartmouth AI Conference)에서는 인공지능에 대한 다양한 접근방안들이 제시되었고 인공지능에 대한 장밋빛 전망이 최고조에 도달했습니다.
4) 1957년: 프랑크 로젠블라트(Frank Rosenblatt)가 로지스틱 회귀의 초기 버전으로 볼 수 있는 퍼셉트론(Perceptron) 발표
5) 1959년: 데이비드 허블(David Hubel)과 토르스텐 비셀(Torsten Wiesel)이 고양이를 사용해 시각 피질에 있는 뉴런 기능을 연구(두 사람은 노벨상을 수상)
퍼셉트론의 한계 등으로 표현되는 컴퓨터의 성능에 대한 한계로 이후 인공지능에 대한 심도있는 연구와 투자가 다소 침체되는 모습을 보였으며, 이후 전문가 시스템(Expert System)의 등장으로 지식활용의 연구가 진행되었으나 이 또한 전문가시스템의 실패로 크게 성공하지는 못했습니다. 1990년대 후반들어서 부터 인공지능은 다시 각광을 받기 시작했고 연구자들은 물론 대중 매체도 어느 때 보다 큰 관심을 가지게 되었습니다. 이제는 영화와 드라마, 소설 속에서 지능을 가진 컴퓨터 시스템이 등장하는 것이 흔합니다. 하지만 영화 속에 등장하는 인공지능을 실생활에서 체험하기는 아직은 어렵지만 지금의 AI관련 기술발전 속도를 감안하면 우리의 실생활에 인공지능 기술이 접목된 IT기기 등을 쉽게 찾아볼 수 있을 것입니다.
머신러닝(Machine Learning) 이란?
컴퓨터는 어떻게 인간과 같은 수준(물론 아직은 결코 충분하지 않지만)의 지식(판단), 사고 등을 할 수 있을까? 하는 의문이 생깁니다. 인간들도 자연스럽게 생성되는 심성(개인별 특성 등)도 있겠지만 학습과정을 통해 사고와 판단을 할 수 있는 지식과 지혜들을 쌓아간다고 불 수 있습니다. 그러면 컴퓨터는 어떻게 지식을 쌓아갈 수 있는 것가요? 컴퓨터라는 기계가 배운다? 머신러닝(machine learning)이란 것을 알아가는 의문점의 시작일 것입니다.
- 기계가 '배운다'라는 것이 정확히 무엇을 의미하는 것일까?
- 컴퓨터가 갑자기 똑똑해질 수 있을까?
- 머신러닝은 어디서 시작하고 어디서 끝나는 걸까?
- 머신러닝이 무엇인가? 왜 머신러닝이 필요한가?
머신러닝(ML)은 인간이 학습하는 방식을 모방하기 위한 데이터와 알고리즘의 사용에 초점을 맞춘 인공지능(AI)의 한 분야로서, 시간이 지남에 따라 점차 정확도를 향상시킵니다. 즉, 머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그램하는 과학(또는 예술)이라고 볼 수 있습니다.
- "머신러닝은 명시적인 프로그램 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구분야이다", 아서 사무엘(Arthur Samuel), 1959
조금 더 공학적인 정의는 다음과 같습니다.
- "어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상되었다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다", 톰 미첼(Tom Mitchell), 1997
머신러닝(machine learning)은 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야이기도 합니다. 또한 머신러닝은 통계학과 깊은 관련이 있습니다. 통계학에서 유래된 머신러닝 알고리즘이 많으며 통계학과 컴퓨터 과학 분야가 상호 작용하면서 발전하고 있습니다. 대표적인 오픈소스 통계 소프트웨어인 R에는 다양한 머신러닝 알고리즘이 구현되어 있습니다. 하지만 최근 머신러닝의 발전은 통계나 수학 이론보다 경험을 바탕으로 발전하는 경우도 많습니다. 컴퓨터 과학 분야가 이런 발전을 주도하고 있습니다. 머신 러닝은 컴퓨터 알고리즘에 많은 양의 데이터를 제공하여 데이터 세트 내에서 패턴과 관계를 식별하는 방법을 배울 수 있도록 합니다. 그런 다음, 알고리즘은 분석을 기반으로 자신만의 예측 또는 결정을 내리기 시작합니다. 알고리즘이 새로운 데이터를 수신하면, 알고리즘은 사람이 연습을 통해 어떤 활동을 더 잘 하게 되는 것과 같은 방식으로 자신의 선택을 계속 개선하고 그 성과를 향상시킵니다.
머신러닝의 분류
인공지능을 설명하고 이해하는 데 반드시 동반되는 용어가 머신러닝과 딥러닝이란 표현입니다. 연구하는 학자 또는 실제 인공지능 시스템을 설계, 개발하는 사람들간 논란의 여지는 있지만 주제영역의 범주 또는 포함관계를 설명하자면 아래와 같이 표현될 것입니다.
인공지능(Artificial Intelligence) > 머신러닝(Machine Learning) > 딥러닝(Deep Learning)
먼저 인공지능이 가장 큰 개념으로 머신러닝 개념을 포함합니다. 인공지능(Artificial intelligence)은 인간의 학습 능력과 추론 능력, 지각 능력 등을 컴퓨터 프로그램으로 실현한 기술을 말하는데 그 연구 분야 중 하나가 바로 머신러닝입니다. 그리고 딥러닝은 앞서 설명해 드린 것처럼 인공신경망을 이용한 머신러닝의 한 종류로 머신러닝의 하위 개념으로 볼 수 있습니다. 딥러닝에 대한 머신러닝과의 관계는 다음 기회에 다시 정리하기로 하고 이번 글에서는 머신러닝 중심으로 자료를 전개해 나갑니다.
머신러닝의 네 가지 유형은 지도 머신러닝, 비지도 머신러닝, 준지도 러닝, 강화 러닝입니다.
첫째, 지도 머신러닝(supervised learning)은 가장 일반적인 유형의 머신러닝입니다. 지도 러닝모델에서 알고리즘은 레이블이 지정된 교육 데이터 세트에서 학습하고 시간이 지남에 따라 정확도를 향상시킵니다. 대상 변수가 이전에 보지 못한 새로운 데이터를 수신할 때 정확하게 예측할 수 있는 모델을 구축하도록 설계되었습니다. 예를 들어, 사람들이 장미와 다른 꽃들의 이미지에 레이블을 붙이고 그 속성을 지정하면, 알고리즘은 레이블이 부착되지 않은 새로운 장미 이미지를 받을 때 장미를 정확하게 식별할 수 있습니다.
둘째, 비지도 머신러닝(Unsupervised Learning)은 레이블이 지정되지 않고 대상 변수가 없는 데이터에서 알고리즘이 패턴을 검색하는 경우입니다. 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주인 것이며, 목표는 로그, 추적 및 메트릭에서 이상 징후를 탐지하여 시스템 문제 및 보안 위협을 탐지하는 것과 같이 인간이 아직 식별하지 못한 패턴과 관계를 데이터에서 찾는 것입니다.
셋째, 준지도 러닝(Semi-Supervised Learning)은 지도 및 비지도 머신러닝을 혼합한 것입니다. 준지도 러닝에서 알고리즘은 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터 양쪽 모두에 대해 교육합니다. 먼저 레이블이 지정된 작은 데이터 집합에서 학습하여 사용 가능한 정보를 기반으로 예측 또는 결정을 내립니다. 그런 다음, 레이블이 지정되지 않은 더 큰 데이터 집합을 사용하여 데이터에서 패턴과 관계를 찾아 예측 또는 결정을 세분화합니다.
넷쩨, 강화 러닝(reinforcement learning)은 알고리즘이 자신의 행동에 대한 보상이나 벌칙의 형태로 피드백을 받아 시행착오를 통해 학습하는 것입니다. 몇 가지 예를 들면, AI 에이전트가 비디오 게임을 하도록 교육시키면서 레벨 향상에 대한 긍정적인 보상과 실패에 대한 페널티를 받는 것, 공급 체인을 최적화하면서 에이전트가 비용을 최소화하고 배송 속도를 최대화하는 것, 또는 추천 시스템을 통해 에이전트가 제품 또는 콘텐츠를 제안하고 구매 및 클릭으로 보상을 받는 경우 등이 있습니다.
결론: 이점과 미래 연구
머신러닝에는 인공지능을 통한 기업이 새로운 효율성을 위해 활용할 수 있는 많은 이점이 있습니다. 인간이 전혀 발견하지 못할 수 있는 방대한 양의 데이터에서 패턴과 추세를 식별하는 머신러닝이 포함됩니다. 그리고 이 분석에는 사람의 개입이 거의 필요하지 않으며, 관심 있는 데이터 세트를 입력하기만 하면 머신러닝 시스템이 자체 알고리즘을 조합하고 개선하며, 시간이 지남에 따라 더 많은 데이터 입력으로 지속적으로 개선됩니다. 모델이 해당 사람에 대한 모든 경험을 통해 더 많이 학습함에 따라 고객과 사용자는 보다 개인화된 경험을 즐길 수 있습니다. 인공지능의 연구 방향에 대해서는 구체적으로 어떤 모습으로 형상화 될 것인가 하는 자체가 성립될 수 없기에 예단하기는 어렵습니다. 머신러닝을 포함한 학습, 지식 축적 등의 연구는 인간의 연구범위를 넘어서고 있는 것이 아닌지 하는 큰 우려를 낳고 있는 것이 사실인 것 같습니다.